
7x24小时咨询热线
400-660-3310
当前位置 : 好学校 南京正厚软件技术培训学校 学习资讯 资讯详情
MySQL作为存储数据的工具,它有自己的书写语言,相信很多小伙伴经过系统学习之后,能够熟练掌握数据库定义语言、数据库操纵语言的语序。但在真正使用SQL过程中,通常要考虑SQL语句的执行效率,特别是查询语句的效率就需要我们了解SQL语句的执行顺序,这样才能写出更好地SQL语句,今天就大致梳理一下MySQL查询语句的执行顺序。
n首先SQL语句的基本语法如下:
1、select 查询字段1,查询字段2,聚合函数,distinct
2、from 表名
3、join on 表名
4、where 条件
5、group by 分组排列
6、having 条件
7、order by 排序(升序降序)
8、limit 结果限定
n按照以上书写顺序,完整的执行顺序应该是这样:
1、from子句识别查询表的数据;
2、join on/union用于连接多表数据;
3、where子句基于指定的条件对记录进行筛选;
4、group by 子句将数据划分成多个组别,如按性别男、女分组;
5、有聚合函数时,要使用聚集函数进行数据计算;
6、Having子句筛选满足第二条件的数据;
7、执行select语句进行字段筛选
8、筛选重复数据;
9、对数据进行排序;
10、执行limit进行结果限定。
n如果还不能理解通过下面的例子就能一目了然:
uselect 查询字段 from 表列表名/视图列表名 where 条件.
执行顺序:先from再where select
uselect 查询字段 from 表列表名/视图列表名 where 条件 group by (列列表) having 条件
执行顺序:先from再where再group by 再having select
uselect 查询字段 from 表列表名/视图列表名 where 条件 group by (列列表) having 条件 order by 列列表
执行顺序:先from再where再group by再having再select order by
uselect 查询字段 from 表1 join 表2 on 表1.列1=表2.列1...join 表n on 表n.列1=表(n-1).列1 where 表1.条件 and 表2.条件...表n.
执行顺序:先from 再join再where select
n就是因为有执行顺序的限制,在书写SQL语句时需要注意一下几点:
uSQL语句是从from开始执行,而不是从select。MySQL在执行SQL查询语句时,首先是将数据从硬盘加载数据缓冲区中,以便对这些数据进行操作;
uSelect是在from和group by 之后执行,这就导致了无法在where中使用select中设置的字段别名作为查询条件。如需要查询男学生的总成绩并要升序排列:select sum(score) as “成绩总和” from score where sex=“男” order by sum(score);
u聚合函数的计算在where子句之后,所以在where子句中就不能使用聚合函数;
uUnion是排在Order by 之前的,虽然数据库允许SQL语句对UNION段中的子查询或者派生表进行排序,但这并不能说明在union操作过后仍保持排序后的顺序。如下图:
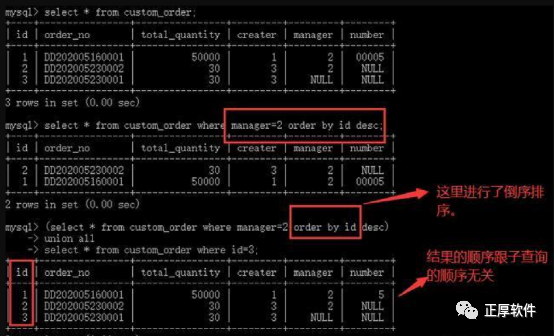
u在MySQL中SQL的逻辑查询时根据以上描述进行的,但MySQL可能并不完全会按照逻辑查询处理方式进行查询。MySQL有2个组件:
a)分析SQL语句的Parser;
b)优化器Optimizer;
MySQL在执行查询之前都会选择一条自认为的查询方案去执行,获取查询结果。一般情况下都能计算出的查询方案;
u存在索引时,优化器优先使用索引的插叙条件,当索引为多个时,优化器会直接选择效率的索引去执行。
相关课程
南京正厚软件技术培训学校
认证等级
南京正厚软件技术培训学校
已获好学校V2信誉等级认证
信誉值
与好学校签订读书保障协议:



















 粤公网安备 44010602004272号
粤公网安备 44010602004272号